Vyhledávací strom, naivní implementace – Wikipedie
Binární vyhledávací strom (Česky Binární vyhledávací strom (BST)) je datová struktura pro práci s uspořádanými množinami.
Binární vyhledávací strom má následující vlastnost: pokud je x uzel binárního stromu s klíčem k, pak všechny uzly v levém podstromu musí mít klíče menší než k a v pravém podstromu větší než k.
Operace v binárním vyhledávacím stromu
Pro reprezentaci binárního vyhledávacího stromu v paměti použijeme následující strukturu:
struct Uzel: T klíč // klíč uzlu Uzel vlevo // ukazatel na levého potomka Uzel přesně // ukazatel na pravého potomka Uzel rodič // ukazatel na předka
Procházení vyhledávacího stromu
Existují tři operace procházení uzlů stromu, které se liší pořadím, ve kterém jsou uzly procházeny:
- [math]mathrm[/math] — procházení uzlů v seřazeném pořadí,
- [math]mathrm[/math] — procházení uzlů v pořadí: vrchol, levý podstrom, pravý podstrom,
- [math]mathrm[/math] — procházení uzlů v pořadí: levý podstrom, pravý podstrom, vrchol.
func inorderTraversal(x : Uzel): if x != null inorderTraversal(x.left) vytisknout x.key inorderTraversal(x.right)
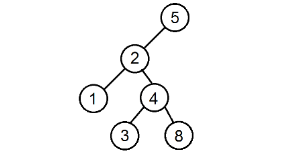
Při provádění tohoto průchodu budou vrcholy vypsány v následujícím pořadí: 1 3 4 67 8.
func předobjednávkovýTraversal(x : Uzel) if x != null vytisknout x.key preorderTraversal(x.left) preorderTraversal(x.right)
Při provádění tohoto průchodu budou vrcholy vypsány v následujícím pořadí: 8 3 1 64 7.
func postorderTraversal(x : Uzel) if x != null postorderTraversal(x.left) postorderTraversal(x.right) vytisknout x.key
Při provádění tohoto průchodu budou vrcholy vypsány v následujícím pořadí: 1 4 7 63 13.
Tyto algoritmy provádějí průchod v čase [math]O(n)[/math], protože procedura je volána přesně dvakrát pro každý uzel stromu.
Hledat prvek
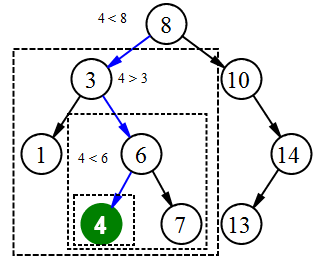
Hledání prvku 4
Pro nalezení prvku v binárním vyhledávacím stromu můžete použít následující funkci, která jako parametry bere kořen stromu a hledaný klíč. Pro každý uzel funkce porovnává hodnotu jeho klíče s hledaným klíčem. Pokud jsou klíče stejné, funkce vrací aktuální uzel, jinak je funkce volána rekurzivně pro levý nebo pravý podstrom. Uzly navštívené funkcí tvoří sestupnou cestu od kořene, takže její doba běhu je √(O(h)ₙ), kde √(h)ₙ je výška stromu.
Uzel vyhledávání(x : Uzel, k : T): if x == null or k == x.klíč zpáteční x if k < x.klíč zpáteční hledat(x.left, k) jiný zpáteční hledat(x.vpravo, k)
Nalezení minima a maxima
Chcete-li najít minimální prvek v binárním vyhledávacím stromu, stačí sledovat ukazatele [math]vlevo[/math] od kořene stromu, dokud nenarazíte na hodnotu [math]null[/math]. Pokud má uzel levý podstrom, pak podle vlastnosti binárního vyhledávacího stromu ukládá všechny prvky s menším klíčem. Pokud ho nemá, pak je tento uzel minimální. Maximální prvek se hledá podobným způsobem. K tomu je třeba sledovat ukazatele vpravo.
Uzel minimum(x : Uzel): if x.left == null zpáteční x zpáteční minimum(x.left)
Uzel maximum(x : Uzel): if x.vpravo == null zpáteční x zpáteční maximum(x.right)
Tyto funkce berou kořen podstromu a vracejí minimální (maximální) prvek v podstromu. Obě procedury běží v čase [math]O(h)[/math].
Najít další a předchozí prvek
Implementace s využitím informací o nadřazené platformě
Pokud má uzel pravý podstrom, pak prvek za ním bude minimálním prvkem v tomto podstromu. Pokud nemá pravý podstrom, pak musíme sledovat, dokud nenarazíme na uzel, který je levým potomkem svého rodiče. Hledání předchozího se provádí podobně. Pokud má uzel levý podstrom, pak prvek před ním bude maximálním prvkem v tomto podstromu. Pokud nemá levý podstrom, pak musíme sledovat, dokud nenarazíme na uzel, který je pravým potomkem svého rodiče.
Uzel další(x : Uzel): if x.vpravo != null zpáteční minimum(x.right) y = x.parent zatímco y != null si x == y.pravý x = yy = y.rodičovský zpáteční y
Uzel předchozí(x : Uzel): if x.vlevo != null zpáteční maximum(x.left) y = x.parent zatímco y != null si x == y.left x = yy = y.parent zpáteční y
Obě operace se provedou v čase [math]O(h)[/math].
Implementace bez použití informací o nadřazené platformě
Uvažujme hledání dalšího prvku pro nějaký klíč [math]x[/math]. Hledání začneme od kořene stromu a uložíme aktuální uzel [math]current[/math] a uzel [math]successor[/math], tedy poslední navštívený uzel, jehož klíč je větší než [math]x[/math].
Projdeme stromem dolů, jako v algoritmu pro vyhledávání uzlů. Uvažujme klíč aktuálního uzlu [math]current[/math] . Pokud [math]current.key leqslant x[/math] , pak uzel vedle [math]x[/math] je v pravém podstromu (v levém podstromu jsou všechny klíče menší než [math]current.key[/math] ). Pokud [math]x lt current.key[/math] , pak [math]x lt next(x) leqslant current.key[/math] , takže [math]current[/math] může být dalším uzlem pro klíč [math]x[/math] , nebo další uzel je obsažen v levém podstromu [math]current[/math] . Přesuňme se na požadovaný podstrom a zopakujeme stejné akce.
Operace hledání předchozího prvku je implementována podobně.
Uzel další(x : T): Uzel aktuální = kořen, následník = null // kořen — kořen stromu zatímco aktuální != null if current.key > x successor = current current = current.left jiný proud = proud.vpravo zpáteční nástupce
vložit
Operace vkládání funguje podobně jako hledání prvku, pouze pokud se zjistí, že prvek nemá potomka, musí se k němu vložený prvek připojit.
Implementace s využitím informací o nadřazené platformě
func vložit(x : Uzel, z : Uzel): // x je kořen podstromu, z je prvek, který má být vložen zatímco x != null if klávesa z > klávesa x if x.vpravo != null x = x.vpravo jiný z.parent = x x.right = z rozbít jinak pokud z.key < x.key if x.vlevo != null x = x.levo jiný z.parent = x x.left = z rozbít
Implementace bez použití informací o nadřazené platformě
Uzel vložit(x : Uzel, z : T): // x je kořen podstromu, z je vložený klíč if x == null zpáteční Uzel(z) // zavěšení uzlu s klíčem = z jinak pokud z < x.key x.left = insert(x.left, z) jinak pokud z > x.key x.right = insert(x.right, z) zpáteční x
Doba běhu algoritmu pro obě implementace je [math]O(h)[/math] .
Odstranění
Nerekurzivní implementace
Pro odstranění uzlu z binárního vyhledávacího stromu musíme zvážit tři možné situace. Pokud uzel nemá žádné podřízené uzly, pak jeho rodičovský uzel jednoduše nahradí ukazatel hodnotou null. Pokud má uzel pouze jeden podřízený uzel, pak je třeba vytvořit nové propojení mezi rodičem odstraňovaného uzlu a jeho podřízeným uzlem. Nakonec, pokud má uzel dva podřízené uzly, pak musíme najít prvek, který za ním následuje (tento prvek nebude mít levého podřízeného uzlu), zavěsit jeho pravého podřízeného uzlu na místo nalezeného prvku a nahradit odstraňovaný uzel nalezeným uzlem. Vlastnost binárního vyhledávacího stromu tak nebude porušena. Tato implementace mazání nezvyšuje výšku stromu. Doba běhu algoritmu je O(h).
| Případ | Ilustrace |
|---|---|
| Odstranění listu | 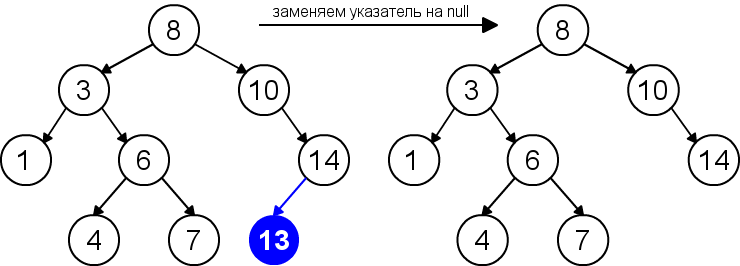 |
| Smazání uzlu s jedním podřízeným uzlem | 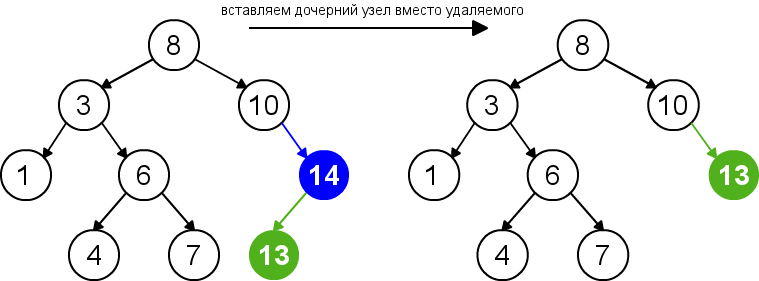 |
| Smazání uzlu se dvěma podřízenými uzly | 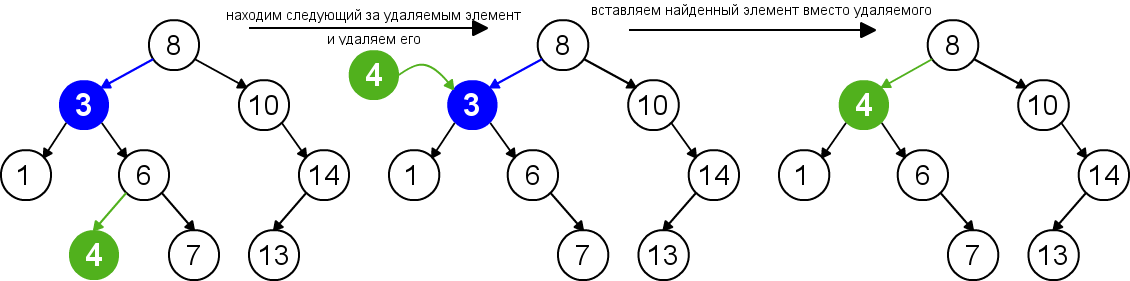 |
func smazat(t : Uzel, v : Uzel): // - dřevo, — prvek, který má být odstraněn p = v.parent // předchůdce odstraňovaného elementu if v.left == null si v.right == null // první případ: element, který má být odstraněn, je list if vlevo == v vlevo = null if pravá strana == v pravá strana = null jinak pokud v.left == null or v.right == null // druhý případ: odstraňovaný prvek má jednoho potomka if v.left == null if vlevo == v vlevo = vpravo jiný p.right = v.right v.right.parent = p jiný if p.levo == v p.levo = v.levo jiný p.vpravo = v.levo v.levo.rodič = p jiný // třetí případ: odstraňovaný element má dva potomky nástupce = další(v, t) v.klíč = nástupce.klíč if nástupce.rodič.left == nástupce nástupce.rodič.left = nástupce.pravý if nástupce.vpravo != null nástupce.vpravo.rodič = nástupce.rodič jiný nástupce.právo.následník = právo nástupce if nástupce.vpravo != null nástupce.vpravo.rodič = nástupce.rodič
Rekurzivní implementace
Při rekurzivním mazání uzlu z binárního stromu je třeba zvážit tři případy: mazací prvek se nachází v levém podstromu aktuálního podstromu, mazací prvek se nachází v pravém podstromu nebo mazací prvek se nachází v kořeni. V prvních dvou případech musí být mazací prvek rekurzivně odstraněn z požadovaného podstromu. Pokud se mazací prvek nachází v kořeni aktuálního podstromu a má dva podřízené uzly, musí být nahrazen minimálním prvkem z pravého podstromu a rekurzivně odstraněn. tento minimální prvek z pravého podstromu. V opačném případě, pokud má odstraňovaný prvek jeden podřízený uzel, musí být nahrazen potomkem. Doba běhu algoritmu je O(h). Rekurzivní funkce, která vrací strom s odstraněným prvkem z:
Uzel smazat(root : Uzel, z : T): // kořen podstromu, klíč k odstranění if kořen == null zpáteční kořen if z < root.key root.left = delete(root.left, z) jinak pokud z > root.key root.right = delete(root.right, z) jinak pokud kořen.left != null si kořen.vpravo != null root.key = minimum(root.right).key root.right = delete(root.right, root.key) jiný if kořen.left != null kořen = kořen.levý jinak pokud kořen.vpravo != null kořen = kořen.vpravo jiný kořen = null zpáteční kořen
Problémy s binárním vyhledávacím stromem
Kontrola, zda je daný strom vyhledávacím stromem
| Úkol: |
| Určete, zda daný binární strom je vyhledávacím stromem. |
Příklad stromu, u kterého nestačí kontrolovat pouze sousední uzly
K vyřešení tohoto problému používáme procházení do hloubky. Spustíme rekurzivní logickou funkci od kořene, která vrátí hodnotu [math]mathtt[/math], pokud je strom BST, a [math]mathtt[/math] v opačném případě. Aby strom nebyl BST, musí mít alespoň jeden vrchol, který nespadá pod definici vyhledávacího stromu. To znamená, že stačí najít pouze jeden takový vrchol, aby se rekurze ukončila a vrátila hodnota [mathtt]mathtt[/math] . Pokud po dosažení listů funkce na své cestě nenarazí na takové vrcholy, vrátí hodnotu [math]mathtt[/math] .
Funkce bere jako vstup zkoumaný uzel a také dvě hodnoty: [math]mathtt[/math] a [math]mathtt[/math], které se před voláním funkce rovny [math] infty[/math] a [math] -infty[/math], kde [math] infty[/math] je velmi velké číslo, tj. žádný klíč stromu ho nepřekračuje v absolutní hodnotě. Zdálo by se, že poslední dva parametry nejsou potřeba. Bez nich by však program mohl vrátit nesprávnou odpověď, protože porovnání pouze uzlu a jeho potomků nestačí. Je také nutné si pamatovat, ve kterém podstromu pro starší předky se nacházíme. Například v tomto stromu je uzel s číslem [math]8[/math] nalevo od uzlu obsahujícího [math]5[/math], který by neměl být ve vyhledávacím stromu, ale po kontrole by funkce vrátila [math]mathtt[/math].
bool isBinarySearchTree(kořen: Uzel): // Zde je kořen kořen daného binárního stromu. bool kontrola(v: Uzel, min.: T, max.: T): // min a max jsou minimální a maximální povolené hodnoty v uzlech podstromu. if v == null zpáteční pravdivý if v.key nebo maximální návrat nepravdivý zpáteční check(v.left, min, v.key) si check(v.right, v.key, max) zpáteční kontrola(kořen, , )
Doba běhu algoritmu je O(n), kde n je počet uzlů ve stromu.
Problémy s nalezením maximálního BST v daném binárním stromu
| Úkol: |
| V daném stromu najděte vrchol takový, aby byl kořenem hledaného podstromu s největším počtem vrcholů. |
Pokud zkontrolujeme každý vrchol výše uvedeným způsobem, můžeme problém vyřešit za [math]O(n^2)[/math] . Lze jej však vyřešit za [math]O(n)[/math] , počínaje od kořene a kontrolou každého vrcholu jednou, na základě následujících faktů:
- Hodnota v uzlu je větší než maximum v jeho levém podstromu;
- Hodnota v uzlu je menší než minimum v jeho pravém podstromu;
- Levý a pravý podstrom jsou vyhledávací stromy.
Zavedeme funkce [math]mathtt[/math] a [math]mathtt[/math], které uloží minimum do levého podstromu uzlu a maximum do pravého. Poté budeme muset zkontrolovat, zda jsou tyto podstromy vyhledávacími stromy, a pokud ano, zda klíč uzlu [math]mathtt[/math] leží mezi těmito hodnotami [math]mathtt[/math] a [math]mathtt[/math] . Pokud je uzel list, automaticky se stává vyhledávacím stromem a jeho klíč je minimum nebo maximum pro jeho rodiče (v závislosti na umístění uzlu). Funkce [math]mathtt[/math] zapíše do [math]mathtt[/math] počet uzlů ve stromu, pokud se jedná o vyhledávací strom, nebo [math]mathtt[/math] jinak. Po spuštění funkce hledáme v lineárním čase uzel s největší hodnotou [math]mathtt[/math] .
int počet(kořen: Uzel): // kořen je kořen daného binárního stromu. int cnt(v: Uzel): if v == null v.kol = 0 zpáteční = 0 if cnt(v.left) != -1 si cnt(v.vpravo) != -1 if v.left == null si v.right == null v.min = v.key v.max = v.key v.kol = 1 zpáteční 1 if v.left == null if v.right.max > v.key v.min = v.key v.kol = cnt(v.right) + 1 zpáteční v.kol if v.right == null if v.left.min < v.key v.max = v.key v.kol = cnt(v.left) + 1 zpáteční v.kol if v.left.min < v.key si v.pravá.max > v.klávesa v.min = v.levá.min v.max = v.pravá.max v.kol = v.levá.kol + v.pravá.kol + 1 v.kol = cnt(v.levá) + cnt(v.pravá) + 1 zpáteční v.kol zpáteční -1 zpáteční cnt(kořen)
Algoritmus běží za čas O(n), protože jsme strom prošli dvakrát za čas rovný počtu vrcholů.
Rekonstrukce stromu na základě výsledku procházení metodou preorderTraversal
| Úkol: |
| Obnovte strom z výstupu sekvence po provedení procedury [math]mathrm[/math]. |
Obnova vyhledávacího stromu z klíčové posloupnosti
Jak si pamatujeme, procedura [math]mathrm[/math] vypíše hodnoty v uzlech podstromu takto: nejprve jde úplně doleva, pak v určitém bodě udělá krok doprava a znovu se posune doleva. Toto pokračuje, dokud nebudou vypsány všechny uzly. Výsledná posloupnost nám umožní jednoznačně určit umístění všech uzlů podstromu. První uzel bude vždy u kořene. Pak, dokud nebudou všechny hodnoty spotřebovány, budeme postupně zavěšovat levé syny na poslední přidaný uzel, dokud nenajdeme číslo, které porušuje klesající posloupnost, a pro každé takové číslo budeme hledat uzel bez pravého potomka, uložíme největší hodnotu, která nepřesahuje tu, kterou chceme umístit, a prvek s takovým číslem na něj zavěsíme jako pravého potomka. Když, když chceme najít takový uzel, narazíme na jiný, který již pravého potomka má, jdeme po větvi doprava. Máme na to právo, protože pokud takový vrchol existuje, pak ho procedura bypass již navštívila a odbočila doprava, takže nemá smysl jít opačnou cestou. Zapamatujeme si vrchol s maximálním klíčem, od kterého začneme hledání. Bude aktualizován pokaždé, když se objeví nové maximum.
Procedura obnovy stromu probíhá za [math]O(n)[/math] .
Analyzujme algoritmus na příkladu posloupnosti [math]mathtt[/math] [math]mathtt[/math] [math]mathtt[/math] [math]mathtt[/math] [math]mathtt[/math] [math]mathtt[/math] .
Červeně zvýrazníme vrcholy uvažované v každém kroku, černě tučně jejich rodiče, kurzívou klesající podposloupnosti (v případech, kdy je uvažujeme) nebo kandidáty na přidání pravého potomka k nim (pokud uvažujeme vrchol, který porušuje klesající posloupnost).
См. также
- Vyhledávání datových struktur
- Randomizovaný binární vyhledávací strom
- Červeno-černý strom
- strom AVL
Zdroje informací
- Wikipedie – Binární vyhledávací strom
- Wikipedie – Binární vyhledávací strom
- Cormen, T., Leiserson, C., Rivest, R., Stein, K. Algoritmy: Konstrukce a analýza = Úvod do algoritmů / Ed. I. V. Krasikov. – 2. vydání. – Moskva: Williams, 2005. – 1296 s. – ISBN 5-8459-0857-4